 2019, Vol. 34
2019, Vol. 34

贝叶斯网络是一种可解释的概率图形模型, 广泛应用于人工智能推理和因果分析中[1-2].在众多的分类模型中, 贝叶斯网络对不确定性推理有着明显的优势[3].它主要用概率刻画因果关系, 并可以处理存在冗余信息或者数据缺失的数据集.贝叶斯网络分为结构学习和参数学习[4]两部分.结构学习是形成一个有向无环图(DAG)的过程, 图中节点代表属性, 有向边代表属性间的条件关系或因果关系.参数学习以条件概率分布刻画属性对其父节点的依赖关系, 通过样本分布的频率表示概率并填充条件概率表.贝叶斯网络模型通常是一个无环图, 这一点是来源于因果论[5]中对概率模型的解释, 表达一个导致结果成立的原因不能反过来成为结果, 所以贝叶斯网络模型也被称为因果网络或信念网络.
自贝叶斯网络[6]被提出以来, 经过近30年的发展形成了很多新算法, 具有代表性的经典算法有朴素贝叶斯模型[7-8]、树增广朴素贝叶斯模型[9-10]和K阶贝叶斯分类模型(KDB)[11-12]. KDB模型较其他模型有更精准的分类能力, 为降低搜索空间, 它利用互信息I(Xi; C)(其中Xi为决策属性, C为类变量)对属性进行降序排列, 使产生的特征子集泛化误差最小[13].近年来, 国内外众多研究人员针对属性排序优化进行了很多研究, 大致可分为两类:第1类是以互信息作为属性预排序测度, 在此基础上, Naghibi等[14]提出为解决搜索整个子集的NP难问题, 采用基于半定规划的并行搜索策略; Tabar等[15]提出对已排序的属性利用遗传算法来构建贝叶斯网络结构.第2类是以条件互信息作为属性排序测度, Zeng等[16]提出以基于粗糙集的条件互信息代替Shannon的条件互信息, 对属性进行排序和选择, 构建模型时在候选特征子集中搜索最优特征子集; Wang等[17]基于互信息链规则提出局部最优搜索策略, 根据条件互信息自适应确定属性最优次序.
上述研究表明, 以互信息或条件互信息作为属性排序测度与提高算法分类精度有着密切的关联[18], 但大多数算法的改进思路, 是仅考虑决策属性和类变量之间的条件依赖或独立关系, 忽略了以决策属性为条件二者之间的相关性, 导致部分有利于决策表达的信息被遗漏.现实情况中, 有利于决策的信息不仅与类变量相关, 更多有价值的信息也与决策属性相关[18], 因此, 强化属性间的关联性有利于决策表达.
此外, 过多的冗余属性(即包含对分类或预测有用信息较少的属性)可能会被赋予更高的决策权, 进而增加模型结构的过拟合风险.属性约简策略可以解决这一问题.属性约简是贝叶斯理论研究核心内容之一[19], 通常用于搜索最优条件子集以替代原条件属性集合, 但用来过滤不确定数据中的冗余属性仍然有效.对给定的属性集合进行约简, 剔除冗余属性.
1 相关理论本文使用{X1, X2, ..., Xn}和C分别表示决策属性和类变量, {x1, x2, ..., xn}和c分别表示相应的取值, n为决策属性个数, 集合用加粗体表示.
1.1 相关定义定义1 互信息I(Xi; C)可用来度量随机变量Xi与C之间的关联程度, 即给定随机变量Xi后, 随机变量C不确定性的削弱程度[20]具体表示为
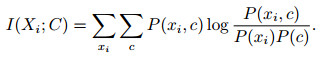
|
(1) |
定义2 条件互信息可用来度量已知随机变量C的条件下, 随机变量Xi和Xj之间的相关程度[20]为
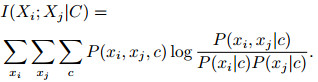
|
(2) |
定义3 决策属性的条件互信息I(Xj; C|Xi), 可用来度量已知决策属性Xi的条件下Xj与类变量C之间的相关程度, 根据定义2转换后表示如下:
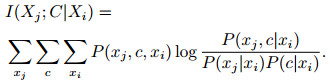
|
(3) |
对于任意给定的联合分布P(c, x1, x2, ..., xn), 利用链规则将其对应的联合分布[20]表示如下:
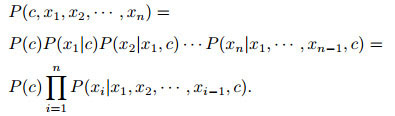
|
(4) |
在式(4)中, 一个属性可能依赖于其他几个属性, 这种依赖关系将传播到整个数据集, 部分数据的轻微变动可能影响整个结果.要找到一个最佳的属性次序需要搜索所有可能的网络结构空间, 没有限制性假设, 从数据中学习贝叶斯网络是NP难问题[21].利用条件独立性假设, 贝叶斯网络将高维联合分布分解成低维局部条件概率分布的乘积, 从而降低了系统整体概率模型的复杂度, 提高了推理效率.例如, 对于一个高维局部条件概率分布
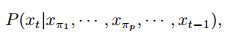
|
(5) |
其中: 1≤ p < t≤ n, {Xπ1, ..., Xπp}为与Xt相关的属性, 假设Xt与Xπp到Xt-1之间的每一个属性相互条件独立, 则可以降低局部条件概率分布的维度, 即
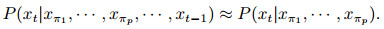
|
(6) |
KDB是允许属性之间进行高阶依赖表达的分类模型, 除类变量C之外, 它允许每个属性节点Xi至多依赖于K个属性(即父节点), 而与其他属性相互独立(即条件独立性假设).目前已有的KDB模型进行结构学习时, 要求按照互信息I(Xi; C)对属性进行降序排列, 利用条件互信息I(Xi; Xj|C)描述属性Xi与Xj之间的相关性.对于任意给定的随机样本集x= (x1, x2, ..., xn), 其对应KDB的联合概率分布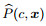
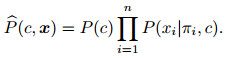
|
(7) |
其中: P(c)为类先验概率, πi为除C之外的Xi的父节点, 父节点的个数由Min(i-1, K)确定.利用条件独立性假设, 图 1描述了当K=2时KDB的示例结构, 对应联合概率分布表示如下:

|
图 1 KDB(K=2)模型示例 |
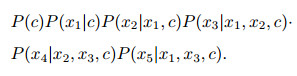
|
通常, 在构建贝叶斯网络模型时希望P(c, x)极大, 即对于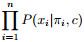
为了便于理解, 考虑仅有{Xi, Xj}两个属性的简单贝叶斯网络局部结构, 其联合概率如下:
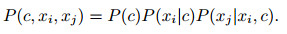
|
(8) |
根据节点的加入顺序分为图 2(a)和图 2(b), 对应的条件概率分别为P(xi|c)和P(xj|xi, c). 图 2(c)展示了相应完整的局部“最优”网络结构, 若要获得最优的结构则要求条件概率P(xi|c)和P(xj|xi, c)极大, 即新加入的节点与已加入的节点关联更紧密, 所以希望对应的互信息I(Xi; C)和I(Xj; Xi, C)极大.

|
图 2 根据节点加入顺序的分组及局部最优结构 |
图 2(a)中的弧对应互信息I(Xi; C), 根据互信息的对称性质, 有I(Xi; C)=I(C; Xi). 图 2(b)中的弧对应互信息I(Xj; Xi, C), 根据互信息的链规则, 有
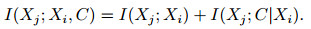
|
(9) |
其中I(Xj; Xi)表示Xi与Xj的关联性, 但I(Xj; Xi)与决策无关可以省略, 即在新加入节点时, 希望相应的I(Xj; C|Xi)极大, 则获得的网络局部结构是“最优”的(如图 2(c)所示).因此, 将图 2(c)中所蕴含的与Xi有关的局部信息(LI)描述如下:
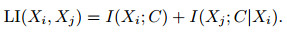
|
(10) |
考虑到Xi与其他任意属性之间的关联性, 与式(10)相对应的全局信息(GI)定义如下:
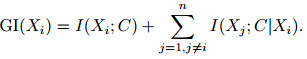
|
(11) |
将GI(Xi)作为描述属性间依赖关系的标准, 既体现了决策属性Xi与类变量C之间的无条件关联性, 又表达了在Xi的影响下, 决策属性Xj与类变量C的条件关联性, 弥补了互信息I(Xi; C)遗漏部分有价值信息的不足.
2.2 基于弱属性的约简策略在贝叶斯网络中, 若使用包含冗余属性的数据集构建模型并进行分类, 将使训练的模型过度拟合, 降低分类性能[22].因此, 本文提出一种基于弱属性的约简策略.根据关联性的大小, 将属性分为强相关属性和弱相关属性.属性的强弱是一个相对概念, 本文分别以15 %、10 %、5 %、1 %的GI进行强、弱属性的划分.实验结果表明, 利用GI*5%(以下简称GI')划分强、弱属性具有更高的分类精度, 其中GI代表所有决策属性的GI(Xi)的均值, 即
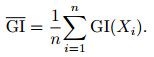
|
(12) |
若属性Xi的GI(Xi)>GI', 则称其为强属性(其包含对分类或预测有用的信息较多); 反之, 称其为弱属性.
通常, 冗余属性包含对分类或预测有用的信息较少, 所以它属于弱属性, 其对应的GI(Xi)的值较小.但若以GI'作为剔除冗余属性的分割值, 当较多属性的GI(Xi)值接近GI'时(此多个属性的GI(Xi)加和远大于GI'), 则易导致多个属性Xi被误删, 进而使模型欠拟合, 影响分类精度.
根据上述描述, 在划分强、弱属性的基础上, 利用GI(Xi)最大的弱属性进行二次判定, 使用W代表弱属性的集合, 该集合包含属性的个数为m, 将W中的属性按照GI(Wi)升序排列, 用{W1, W2, ..., Wm}表示, 其中0≤ m < n.以GI(Wm)为均值构建相对强属性集S和弱属性集W的分布图, 如图 3所示.

|
图 3 相对强属性集和弱属性集的分布 |
假设相对强属性集S的属性个数为u, 对应的属性序列{S1, ..., Su}应满足
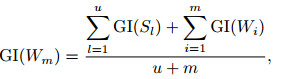
|
(13) |
进而可得
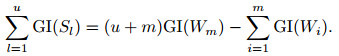
|
(14) |
利用GI(Wm)和弱属性集W求出满足式(14)的u及相应的属性序列, 用Xi'表示{S∪W}中的属性, 则可以得到Xi'对应的GI(Xi')的方差, 即
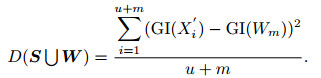
|
(15) |
相应的均方差(即标准差)为
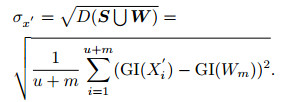
|
(16) |
根据σ原则[23], 利用GI(Wm)-σx'和GI(Wm)+σx', 将图 3的分布曲线与横轴所围成面积分为3个部分(即图中的H1, H2, H3).其中H1代表假设GI(Wi) < GI(Wm)-σx', 根据单边检验(此时H1表示左侧检验)原则, H1对应区域表示拒绝域, 即发生概率很小的区域, {H2+H3}对应区域表示接受域.同时, H1区域内的Wi距离Wm较远, 其GI(Wi)值较小, 对应的互信息I(Wi; C)和决策属性的条件互信息I(Wj; C| Wi)都较小, 其对分类结果的影响更小, 属于冗余属性的可能性更大, 可以被剔除; 否则, Wi应该被保留.
3 算法KDBSM的描述利用上述相关定义, 本文提出强化属性依赖的K阶贝叶斯网络分类模型(KDBSM), 对KDBSM算法的模型构造过程简单描述如下:首先利用GI(Xi)对数据集中的决策属性进行排序, 并根据弱属性的拒绝域进行冗余判定和约简.由于排在最前的K个属性构成的局部结构是完全的, 不需要进行因果推断.从第K+1属性开始, 根据贪心搜索策略确定这些属性的K个父节点.相应的KDBSM算法的具体构造步骤如下:
输入:训练样本集T, 属性集X={X1, X2, ..., Xn}, 属性最大允许依赖数K;
输出: KDBSM模型及对应的条件概率表.
Step 1:将类变量C加入KDBSM, 对任意的决策属性对Xi, Xj∈X, 分别计算对应的I(Xi; C)、I(Xi; Xj|C)、I(Xi; C|Xj).
Step 2:对于任意Xi∈X, 若Xi属于弱属性且其GI(Xi)处于拒绝域内, 则从X中剔除Xi.
Step 3:根据GI(Xi)对X中的决策属性降序排列, 选取前K个属性作为模型的前K个节点.在X中去掉这K个属性.
Step 4:将C作为模型中所有节点的父节点, 构建父节点C与前K个节点的完全局部结构.
Step 5:重复以下步骤直到X为NULL.
Step 5.1:在已有的KDBSM模型空间下, 根据贪心搜索策略在X中选择GI(Xi)最大的属性Xi作为模型的下一节点.选择已有模型结构中I(Xj; Xi|C)最大的前K个属性Xj作为Xi的父节点.
Step 5.2:将Xi添加到模型中并在X中删除, 添加一条由C指向Xi的弧和K条Xj指向Xi的弧.
Step 6:输出模型KDBSM, 根据KDBSM结构计算得到条件概率表.
该算法的复杂度主要在于计算Step 1中的I(Xi; Xj|C)和I(Xi; C|Xj), 其所需的时间复杂度均为O(n2sncv2), 其中n表示决策属性个数, s表示样本个数, nc表示类标签个数, v表示属性的可能取值. Step 2和Step 3中仅需遍历n个属性, 其时间和空间复杂度均为O(n). Step 5涉及的属性选择不会增加额外的空间开销, 时间复杂度为O(n2).另外, 计算条件概率表所需的时间复杂度为O(n(s+vk)).所以, 该算法的时间复杂度为O(n2sncv2), 在许多领域v是一个很小的值, k是用户自定义参数.在实际构建模型时, 对单个实例进行分类时仅需要O(nnck)的时间.较小的计算复杂度使该算法适合于数据挖掘领域.
4 实验分析本文从UCI机器学习数据库[24]中选取21个数据集来验证算法的性能.这些数据集的样本个数、属性个数、类标签个数各不相同, 具体信息如表 1所示.数据集包括离散型和连续型两种类型, 其中离散型属性的缺失值由训练样本集中出现频率最多的属性值来代替, 连续型属性的缺失值由训练样本集中该属性所有取值的平均值来代替.对于每个数据样本, 使用MDL准则对连续型属性进行离散化预处理[25-26].
| 表 1 UCI数据集 |
用于进行比较实验的分类器是:朴素贝叶斯分类模型(NB); 树增广朴素贝叶斯分类模型(TAN); K阶依赖贝叶斯分类模型(KDB); Duan等[27]给出的K-dependence forest(KDF).
4.1 评估函数对于模型预测问题, 如果能获得所有可能的数据集合, 并在这个数据集合上将误差最小化, 这样学习到的模型称为“真实模型”.但实际上, 无法获得并训练所有可能的数据, 所以真实模型肯定存在但无法获得.本文的目标就是学习一个模型, 选取合适的评估函数, 使其误差最小, 并尽可能接近真实模型.本文采用0-1损失函数对所构建模型的性能进行评估, 假设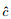
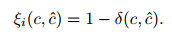
|
(17) |
若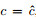
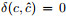
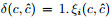
用本文提出的算法KDBSM与上述经典算法进行比较, 为了排除单次结果的偶然性, 通过10折交叉验证(10-fold cross validation)获得算法性能的准确估计. 表 2列出了各个算法在所选取数据集上0-1损失的平均值(注:由于不同语言间的取值精度不同, 各数据集结果可能存在±0.5 %的误差).其中K1DB、K2DB分别代表K=1和K=2阶的KDB算法, K1DF、K2DF分别代表K = 1和K = 2阶的KDF算法, K1DBSM、K2DBSM分别代表K=1和K=2阶的KDBSM算法.
| 表 2 平均0-1损失实验结果 |
表 2所对应的W/D/L统计结果如表 3所示, 其中W/D/L代表Win/Draw/Loss, 是指在相同条件下对相同的数据集, 分类器A的0-1损失分别明显优于/接近/明显劣于分类器B的数据集的计数.需要指出的是:各个算法均以95 %的置信度进行比较, 不同算法对同一个数据集交叉验证的方式是相同的.由表 3分析可以得到如下结论:在21个数据集中, 对于模型KDBSM, 在K=1阶时分类准确度显著优于KDB(6/ 15/0)和KDF(6/13/1);在K=2阶时分类准确度明显优于KDB(8/12/1)和KDF(4/17/0), 仅有一个数据集Autos的分类准确度劣于KDB, 因为在KDB和KDF中该数据集属性间的关联程度已最大.综上所述, 算法KDBSM具有更好的分类精度.
| 表 3 平均0-1损失的W/D/L比较结果 |
因为KDBSM算法是在KDB上进行改进, 所以下面针对不同实例规模下, 该算法相对于KDB在分类准确度上的差异性进行分析, 仅依靠0-1损失无法反应算法在不同实例规模下分类准确度的不同.为了说明不同实例规模下, 算法KDBSM与KDB分类准确度的差异性, 本文定义算法净胜数
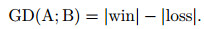
|
(18) |
其中: |win|和|loss|分别代表算法A在0-1损失上优于和劣于算法B的数据集个数, GD是比较两个分类器在不同规模数据集上性能的评分准则, GD曲线趋势越向上代表A比B越有优势.
图 4中列出了K=1, 2时, 算法KDBSM对KDB的GD曲线, 将数据集按实例规模从小到大排序, 横、纵坐标分别代表数据集序号和净胜数GD.就图中曲线的总体趋势而言, 两条GD趋势线均由平缓到上升, 随着数据集实例规模的增加, 算法KDBSM的优势更加明显, 其鲁棒性也更为突出.具体地, 在实例规模大于600 (序号大于10)时, 两条GD趋势线开始上升, 因为实例规模小于600时, 数据集中仍包含一定数量的冗余属性; 当实例规模大于600后, 属性间的依赖关系强化明显, 更多的冗余属性被检测到并被剔除, 模型结构优化明显, 算法KDBSM的分类准确度更高.特别地, 当K为1阶时, 对于数据集实例规模大于600且小于1 000 (序号大于10且小于13)和大于48 800 (序号大于19), 算法KDBSM优势突出; 当K为2阶时, 对于实例规模大于1 000且小于5 000 (序号大于13且小于17), 算法KDBSM比KDB的优势更明显, 其分类也更准确.

|
图 4 K为1阶和2阶时KDBSM对KDB的GD曲线 |
图 4中的GD趋势线从实例规模为600 (序号大于10)时开始上升, 即算法KDBSM相对于KDB的分类精度明显提升, 但GD趋势线无法反应提升的程度.因此, 本文将不同实例规模下算法分类精度的提升程度定义为提升比, 即
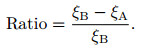
|
(19) |
其中: ξA、ξB分别代表A、B算法的0-1损失, 若Ratio >0, 则代表分类器A相对于分类器B的分类精度有所提升, Ratio越大代表提升程度越显著.
为了进一步说明实例规模大于600时, KDBSM相对于KDB的分类精度的提升比, 图 5描述了相应数据集的Ratio, 图中K1Ratio、K2Ratio分别代表K=1和K=2时, 这两个算法在分类精度上的Ratio.将数据集按实例规模从小到大排列, 横坐标表示相应的数据集序号, 纵坐标代表Ratio值.总体而言, 在K=1和K=2时分别有9和7个数据集的分类精度有所提升.具体的, 当K=1时, 有5个数据集KDBSM相对于KDB的分类精度提升13 % (即Ratio>0.13)以上; 当K=2时, 有5个数据集分类精度提升10 %左右, 其中3个数据集的实例规模在2 300到5 000之间(序号大于4且小于7).

|
图 5 K为1阶和2阶时KDBSM相对于KDB的分类精度的提升比 |
本文针对KDB排序属性时, 仅考虑直接相关而忽略条件相关的问题, 提出了KDBSM算法.该算法在强化属性依赖关系的基础上引入属性约简策略, 剔除冗余属性并降低模型过拟合风险; 利用GI(Xi)排序属性, 既体现了决策属性Xi与类变量C之间的无条件关联性, 又表达了在Xi的影响下, 决策属性Xj与类变量C的条件关联性; 该模型具有较好的分类准确度和突出的鲁棒性.进一步的研究是如何构建更合理的冗余判定规则和提高小规模数据集分类精度.
| [1] |
Zhao Y, Chen Y, Tu K, et al. Learning Bayesian network structures under incremental construction curricula[J]. Neurocomputing, 2017, 258(1): 30-40. |
| [2] |
Fan X B, Li X. Network tomography via sparse Bayesian learning[J]. IEEE Communications Letters, 2017, 21(4): 781-784. DOI:10.1109/LCOMM.2017.2649494 |
| [3] |
肖蒙, 张友鹏. 基于因果影响独立模型的贝叶斯网络参数学习[J]. 控制与决策, 2015, 30(6): 1007-1013. (Xiao M, Zhang Y P. Parameters learning of Bayesian networks based on independence of causal influence model[J]. Control and Decision, 2015, 30(6): 1007-1013.) |
| [4] |
Zhao Y, Chen Y, Tu K, et al. Curriculum learning of Bayesian network structures[C]. Asian Conf on Machine Learning. Hong Kong: ACML, 2015: 269-284. http://web.cs.iastate.edu/~jtian/papers/acml-15.pdf
|
| [5] |
Hagmayer Y. Causal Bayes nets as psychological theories of causal reasoning: Evidence from psychological research[J]. Synthese, 2016, 193(4): 1107-1126. DOI:10.1007/s11229-015-0734-0 |
| [6] |
Pearl J. Probabilistic reasoning in intelligent systems: Networks of plausible inference[C]. Networks of Plausible Inference. San Francisco: Morgan Kaufmann, 1988: 383-408.
|
| [7] |
Zhang H. The optimality of naive Bayes[C]. Proc of 17th Int Florida Artificial Intelligence Research Society Conf. Miami Beach: AAAI Press, 2004: 562-567.
|
| [8] |
Jiang L, Li C, Wang S, et al. Deep feature weighting for naive Bayes and its application to text classification[J]. Engineering Applications of Artificial Intelligence, 2016, 52(6): 26-39. |
| [9] |
Jiang L, Cai Z, Wang D, et al. Improving Tree augmented Naive Bayes for class probability estimation[J]. Knowledge-Based Systems, 2012, 26(2): 239-245. |
| [10] |
de Campos C P, Corani G, Scanagatta M, et al. Learning extended tree augmented naive structures[J]. Int J of Approximate Reasoning, 2016, 68(1): 153-163. |
| [11] |
Rodriguez J D, Perez A, Lozano J A. Sensitivity analysis of k-fold cross validation in prediction error estimation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2010, 32(3): 569-575. DOI:10.1109/TPAMI.2009.187 |
| [12] |
Sahami M. Learning limited dependence Bayesian classifiers[C]. Proc of the 2nd Int Conf on Knowledge Discovery and Data Mining. Portland: ACM, 1996: 335-338. https://www.researchgate.net/publication/2340349_Learning_Limited_Dependence_Bayesian_Classifiers
|
| [13] |
Martınez A M, Webb G I, Chen S, et al. Scalable learning of Bayesian network classifiers[J]. J of Machine Learning Research, 2016, 17(44): 1-35. |
| [14] |
Naghibi T, Hoffmann S, Pfister B. A semidefinite programming based search strategy for feature selection with mutual information measure[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015, 37(8): 1529-1541. DOI:10.1109/TPAMI.2014.2372791 |
| [15] |
Tabar V R, Mahdavi M, Heidari S, et al. Learning bayesian network structure using genetic algorithm with consideration of the node ordering via principal component analysis[J]. J of the Iranian Statistical Society, 2016, 15(2): 45-62. DOI:10.18869/acadpub.jirss.15.2.45 |
| [16] |
Zeng Z, Zhang H, Zhang R, et al. A hybrid feature selection method based on rough conditional mutual information and naive Bayesian classifier[J]. Isrn Applied Mathematics, 2015, 2014(1/2/3/4): 36-46. |
| [17] |
Wang L, Zhao H. Learning a flexible K-dependence Bayesian classifier from the chain rule of joint probability distribution[J]. Entropy, 2015, 17(6): 3766-3786. DOI:10.3390/e17063766 |
| [18] |
Vinh N X, Zhou S, Chan J, et al. Can high-order dependencies improve mutual information based feature selection?[J]. Pattern Recognition, 2016, 53(C): 46-58. |
| [19] |
Ziarko W. Attribute reduction in the Bayesian version of variable precision rough set model[J]. Electronic Notes in Theoretical Computer Science, 2003, 82(4): 263-273. DOI:10.1016/S1571-0661(04)80724-2 |
| [20] |
Shannon C E, Weaver W. The mathematical theory of communication[M]. Illinois: University of Illinois Press, 1949: 81-108.
|
| [21] |
Chickering D M, Heckerman D, Meek C. Large-sample learning of Bayesian networks is NP-hard[J]. J of Machine Learning Research, 2004, 5(10): 1287-1330. |
| [22] |
Zhang S, Mccullagh P, Callaghan V. An efficient feature selection method for activity classification[C]. Proc of the 10th Int Conf on Intelligent Environments. Shanghai: IEEE, 2014: 16-22. https://www.academia.edu/12735472/An_Efficient_Feature_Selection_Method_for_Activity_Classification
|
| [23] |
Kriegel H P, Kunath P, Renz M. Probabilistic nearest-neighbor query on uncertain objects[C]. Int Conf on Database Systems for Advanced Applications. Bangkok: DBLP, 2007: 337-348. https://www.researchgate.net/publication/220787485_Probabilistic_Nearest-Neighbor_Query_on_Uncertain_Objects
|
| [24] |
Murphy S L, Aha D W. UCI repository of machine learning databases[EB/OL].[2017-10-10]. http://archive.ics.uci.edu/ml/datasets.html.
|
| [25] |
Fayyad U M, Irani K B. Multi-interval discretization of continuous-valued attributes for classification learning[C]. Proc of the 13th Int Joint Conf on Artificial Intelligence. Chambéry: Morgan Kaufmann, 1993: 1022-1029. http://yaroslavvb.com/papers/fayyad-discretization.pdf
|
| [26] |
Hu B, RaKthanmanon T, Hao Y, et al. Towards discovering the intrinsic cardinality and dimensionality of time series using MDL[M]. Berlin Heidelberg: Springer, 2013: 184-197.
|
| [27] |
Duan Z, Wang L. K-dependence Bayesian classifier ensemble[J]. Entropy, 2017, 19(12): 651. DOI:10.3390/e19120651 |
| [28] |
Li L, Zhang L, Li G, et al. Probabilistic classifier chain inference via gibbs sampling[C]. Proc of the 23rd ACM Int Conf on Information and Knowledge Management. Shanghai: ACM, 2014: 1855-1858. https://dl.acm.org/citation.cfm?id=2661917
|