 2020, Vol. 35
2020, Vol. 35

知识图谱(knowledge graphs, KGs)存储着大量结构化知识, 这些结构化知识已成功地应用于知识推理[1]、问答[2]和推荐[3]等领域.目前, 出现了一些典型的大规模知识图谱, 如YAGO[4]、DBpedia[5]和Freebase[6].在这些知识图谱中, 结构化知识可表示为三元组(h, r, t), 表示其头实体h与尾实体t之间存在关系r.但随着知识图谱中数据量的不断增加, 长尾效应、推理困难和计算量巨大等问题也随之产生[7].为了解决这些问题, Bordes等[8]提出了知识表示学习模型(knowledge representation learning, KRL). KRL的关键思想是将知识图谱中结构化三元组表示为低维向量(称为嵌入), 同时保留原有三元组之间的语义信息.由于知识表示学习方法在低维语义空间中能够高效计算实体和关系的语义联系, 使大规模知识图谱得到更有效的利用, 受到学术界和工业界的高度关注.
现有知识表示学习方法更关注于单个知识图谱的嵌入, 但随着知识图谱应用环境更加多样化, 单个知识图谱中的知识可能很难满足各种需求.因此, 一些研究工作将不同来源的知识图谱(如YAGO、DBpedia)嵌入到低维空间, 通过计算实体之间的相似性实现实体对齐, 并取得了较好的效果.然而, 大部分基于知识表示学习的实体对齐方法仅使用单一模态的数据(如文本), 而忽视了其他模态的数据(如图像), 导致其他模态数据中的实体特征信息未被有效利用.为了弥补实体对齐数据模态较为单一的不足, 本文将多模态实体对齐作为主要研究内容.多模态实体对齐的研究能够帮助实现多模态知识图谱的构建和补全, 并且有利于基于知识图谱应用技术的提升[9-10].
多模态实体之间不可避免地存在着异构性, 因此, 如何消除多模态数据之间的异构性成为一项关键挑战.现有的多源知识图谱实体对齐任务大部分使用多源实体来实现[11-14].由于能够对齐的多源实体之间具有相同或相似的语义信息, 将其嵌入到连续的低维向量语义空间中, 实体对齐任务变成了一种向量平移问题.通过计算两个实体之间的相似度便能实现多源知识图谱实体对齐, 同时还能保留原有的语义信息.因此, 本文遵循基于知识表示学习的多源实体对齐方法, 使用多模态实体对(图像-文本实体对), 在统一低维语义空间中计算多模态实体之间的相似性以实现多模态实体对齐.但如果训练集中能够实现对齐的多模态实体全部由人工进行标注, 则是不可能完成的任务且造成巨大的浪费.为了解决这一问题, 受Bootstrapping算法[15]的启发, 本文设置一个小型的由人工进行标注的多模态对齐种子集合.
本文的主要贡献如下:
1) 提出一种联合知识表示学习模型(joint knowledge representation learning, JKRL), 使得多模态三元组知识能够嵌入到统一的低维语义空间.该模型结合TransE[8]和TransD[16]两种知识表示学习模型中实体距离计算方法, 并为这两种距离计算方法设置相应的权重, 利用各自模型中的优点实现多模态知识的最优嵌入.
2) 提出一种迭代实体对齐规则(iterative entity alignment, IEA).通过迭代地学习已对齐多模态实体间的链接映射关系, 并将这种关系应用到未对齐实体上以发现更多可对齐的多模态实体, 这些新发现的对齐多模态实体可以用来帮助下一轮次的对齐学习.
1 相关工作 1.1 实体对齐实体对齐又称为实体匹配或实体解析, 用于判断两个相同或不同知识库中的实体是否指代同一个对象.传统实体对齐方法通常需要大量人工对数据进行标注或精心设计对齐特征. Yago3方法[17]通过人工精心设计了对齐特征, 使Wikipedia中的实体与已有YAGO中的实体实现对齐, 并取得了较高的对齐准确率.基于网络语义标签的多源知识库实体对齐模型[18]利用多种实体标签, 实现中文实体对齐并取得了较高的准确率和召回率.这类传统实体对齐方法可以实现较高的实体对齐效果, 但使用人工进行数据标注会造成时间的大量浪费和高昂的劳动力成本, 同时, 设计出的实体特征往往扩展性较差, 不具备普遍适用性.
近些年, 也有一些方法专注于在不同知识图谱中使用异源、异构知识进行实体对齐.通过概念标注实现多源实体对齐的方法[19]利用概念注释来丰富知识图谱中的内部链接, 迭代预测新的多源知识对.使用这种迭代对齐的方法虽然可以达到较高的准确率, 但常常需要消耗大量的训练时间.随着知识表示学习方法的提出, MTransE方法[20]直接使用已知的知识三元组实现英语-法语的多语言知识对齐. IPTransE方法[21]使用共享参数实现知识嵌入, 并使用一种软规则的方法实现实体对齐. HolisticEM方法[22]只使用知识图谱中的结构化信息实现三元组知识的向量化表示, 并迭代地实现多源实体对齐. JAPE方法[23]在统一的语义空间中学习实体的嵌入以及不同知识图谱之间的关系, 该方法利用实体属性来细化实体嵌入, 但当不同知识图谱之间的相关实体属性不同时, 实体嵌入的效果会大大下降.
与以往实体对齐模型相比, 本文为了克服训练集中多模态对齐实体数量的不足, 提出一个多模态对齐种子实体集合.通过学习集合内已对齐多模态实体之间的链接映射关系, 标记可能的对齐多模态实体并迭代地将其添加到种子集合中以帮助多模态数据的嵌入.
1.2 知识表示学习近些年, 以深度学习为代表的知识表示学习方法迅速发展并取得了巨大进步.目前, 知识表示学习方法从形式上来讲主要分为基于结构的知识表示学习和基于语义的知识表示学习(如: neural tensor networks (NTN)[24]、semantic space projection(SSP)[25]等).本文使用结构化三元组知识进行知识表示学习, 因此, 将详细介绍基于结构化的知识表示学习方法.
1.2.1 基于翻译模型的方法TransE是基于翻译模型的代表, 该方法将实体和关系嵌入到连续低维空间, 并将关系视为头实体到尾实体的一种翻译. TransE在处理一对一的问题上表现出了显著的优越性, 但在处理复杂关系(如: 1-N、N-1、N-N)时存在适用性不足的问题.为了解决TransE处理复杂关系不理想的问题, TransH方法[26]在嵌入空间中设置了一个超平面, 所有关系均在超平面上, 并在超平面上进行向量计算, 即头实体和尾实体投影到超平面上并进行平移. TransE和TransH模型都将实体和关系嵌入到相同语义空间中, 但实体和关系是不同属性的对象, 不能简单地嵌入到相同的语义空间中.为此, TransR/CTransR方法[27]为每种关系设置了不同的语义空间. CTransR是对TransR的进一步改进, 把关系细分为多个子关系并为每个子关系学习相应的向量表示. TransR/CTransR方法区分了实体和关系, 在处理复杂关系上得到了较大的提升, 但由于需要进行矩阵乘法操作, 导致计算量较大、耗时较长.
1.2.2 基于卷积模型的方法目前除了翻译模型外, 也出现了一些其他的知识表示学习模型, 其中基于卷积模型的方法在部分问题的处理上优于翻译模型. ConvE方法[28]将嵌入得到的向量重构成n维矩阵, 通过卷积神经网络的方法提取特征, 根据提取的特征实现知识的表示. ConvKB方法[29]通过卷积神经网络的方法捕获实体和关系在嵌入空间中的全局关系和过渡特征, 更好地实现知识图谱的补全.但由于卷积神经网络需要进行卷积计算, 训练成本远远高于翻译模型, 且进行卷积操作需要的训练数据量也较为庞大.
考虑到训练数据量及训练成本问题, 本文使用基于翻译模型的方法实现多模态结构化知识的嵌入.与以往基于翻译模型的知识表示学习方法不同, 本文提出的联合知识表示学习模型, 能够同时将文本知识和图像知识嵌入到相同的语义空间中, 消除二者之间的异构性, 在同一个低维语义空间中利用相似度计算来实现对齐, 提高了计算效率.
2 问题描述本文研究的重点问题是如何利用知识表示学习模型来消除多模态实体间的异构性, 并基于迭代对齐规则实现多模态实体对齐.值得提出的是:以往多源知识图谱实体对齐是在相同模态(如文本)下实现多个知识图谱的融合; 而本文任务是挖掘不同模态、不同结构知识间实体的链接映射关系, 从而实现多模态实体的对齐.现有基于实体图像的知识表示学习方法大多使用单实体图像, 即图像中只有一种实体, 这样便于实体识别; 同时, 对实体的领域也进行了限制, 大部分使用易于视觉描述的实体[30-32].本文将使用动物、植物等领域实体实现多模态实体对齐.
本文提出的基于联合知识表示学习的多模态实体对齐(ITMEA)方法的总体框架如图 1所示, 以图像数据集ImageNet[33]和文本数据集WordNet[34]作为输入源, 并将这两个数据集进行联合.其中, 假设在新构建的多模态数据集中, 已知图像实体S1与文本实体I1 (“灯芯草雀”)为已对齐的多模态实体, 但图像实体S2与文本实体I2 (“雀科”)能否实现对齐尚不确定.因此, 对联合数据集中的图像实体使用图像特征提取方法得到相应的图像实体初始向量, 文本实体则通过初始化嵌入得到相应的文本实体初始化向量.对得到的图像实体和文本实体的初始化向量按照结构化三元组的形式再次嵌入到统一低维语义空间, 使图像实体向量和文本实体向量具有相应的语义关系, 消除了图像与文本之间的异构性.通过迭代学习图像实体S1与文本实体I1之间的链接映射关系, 发现图像实体S2与文本实体I2也能够建立这样的链接映射关系, 同时将新发现的多模态对齐实体添加到种子集合中, 并指导下一轮次的多模态知识嵌入.

|
图 1 总体框架 |
首先, 对本节中使用到的符号进行介绍.其中: S代表图像实体集合; I代表文本实体集合; R表示所有关系的集合; E表示所有实体的集合, 即E∈S, I.本文将嵌入维度表示为n, 将初始化实体转换矩阵表示为M.
3.1 基于VGGNet的图像特征提取图像中包含着重要的语义信息, 对实体外形和特征等信息的传递比文本知识更加直观、形象.因此, 在本文方法中使用图像知识作为其中一个输入源.
为了更好地实现图像特征提取, 本文对每个图像实体进行图像特征表示, 使图像实体初始化嵌入成4 096维的向量, 实现图像特征向量化表示.但此时图像特征的维度较高, 无法直接与文本实体建立一定的链接关系, 因此需要进行图像特征投影, 把4 096维的图像特征向量映射为n维的实体嵌入向量.其中, 图像特征表示采用图像实体识别方法VGGNet[35], 图像特征投影则由包含n个神经元的单层神经网络来完成.
3.1.1 基于VGGNet的图像特征表示图像特征表示的目的是对图像实体特征进行提取.本文使用基于卷积神经网络的图像实体识别模型VGGNet, 该模型由5个卷积层、3个全连接层和1个softmax层组成.在图像预处理阶段, 本文受Shutova等[36]和Xie等[37]的启发, 把图像的中心和边缘重构成224×224的尺寸, 将VGGNet方法的第2个全连接层(fc7)输出的向量作为图像实体特征向量.
3.1.2 基于神经网络的图像特征投影图像特征投影的目的是把通过图像特征表示得到的图像特征向量投影到实体空间, 便于进行图像-文本实体对齐.本文通过神经网络的方法在图像特征空间与实体特征空间之间搭建一个桥梁, 即将图像特征的4 096维转换为实体空间的n维, 其定义为
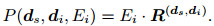
|
(1) |
其中: R(ds, di)是一个转换矩阵, ds表示图像特征维度, di表示实体特征维度, Ei表示第i个实体得到的图像特征表示.
3.2 联合知识表示学习以往知识表示学习方法是在单一模态(如:文本、图像)或单一数据源(如: WordNet、DBpedia等)中进行嵌入化表示.但由于图像知识与文本知识之间存在异构性, 如果分别对二者进行单独嵌入, 则会使实体对齐变得极为困难[37].因此, 本文提出一种多模态联合知识表示学习模型, 旨在将图像知识和文本知识能够嵌入到统一的低维语义空间, 消除两者之间的异构性.如图 2所示, 该联合知识表示学习模型结合TransE和TransD中实体距离计算方法, 使图像知识和文本知识能够同时嵌入到统一的低维语义空间.

|
图 2 联合知识表示学习模型 |
TransE模型使用简单的向量平移(翻译)思想实现知识三元组的表示, 但这种思想处理简单关系更为实用.与TransE相比, TransD模型设置了一个动态映射矩阵, 将知识三元组按照关系映射到不同低维空间, 对复杂问题的处理更为有效.本文认为图像与文本的对齐关系是一种简单关系, 而图像实体之间与文本实体之间更多的是复杂关系.多模态知识仅使用TransE模型或TransD模型并不能很好地实现实体和关系的准确嵌入, 因此, 在本文提出的JKRL方法中结合使用TransE模型和TransD模型, 并设置了相应的权重, 从而更好地实现多模态知识的嵌入.具体来说, 本模型为距离计算方法设置权重α, α的取值范围为[0.00, 1.00], 采用网格搜索算法得到最优权重, 设置网格搜索的步长为k. JKRL的距离计算方法定义为
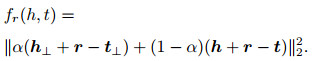
|
(2) |
其中: h⊥+r-t⊥为TransD的距离计算方法, h⊥和t⊥分别为h⊥=Mrhh和h⊥=Mrtt, Mrh和Mrt则分别表示头实体和尾实体所对应的空间转换矩阵. TransD模型为每个关系设置了一个不同的映射矩阵, 使得实体通过映射矩阵嵌入相应关系空间, 这样, 不同属性的同一实体将会表示为不同向量. h+r-t为TransE的距离计算方法.损失函数定义为
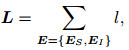
|
(3) |
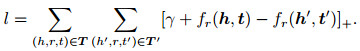
|
(4) |
其中: L表示损失函数, 损失函数趋近于零时, 模型效果最优; E表示图像实体EI和文本实体ES的集合; γ是正例与负例之间的最小间隔, 正例表示知识图谱中已有的结构化三元组, 负例表示训练过程中随机生成的错误三元组, 其形式化定义为
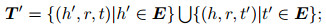
|
(5) |
[x]+表示当得到的值为正值时取原值, 否则为零, 这样能够使得正例与负例区分开.
3.3 迭代实体对齐实体对齐的目的是构造图像实体特征向量与文本特征向量间的链接映射关系.本文在联合嵌入结果的基础上, 根据多模态实体在低维语义空间中的距离, 实现图像-文本多模态实体对齐.本文提出的IEA方法的距离计算公式为
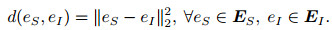
|
(6) |
本文的对齐规则如图 3所示.

|
图 3 对齐规则 |
对于未对齐的图像实体eS, 会遍历整个文本实体集合, 计算每个文本实体向量与该图像实体向量之间的距离, 对计算结果进行升序排列, 并取前m个实体组成候选对齐实体集合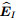
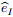
ITMEA方法使用结构化多模态三元组{(hS, r, tS), (hS, r, tI)}和{(hI, r, tS), (hI, r, tI)}作为数据输入.在数据初始化过程中, 将正确三元组的头实体或尾实体进行替换以形成负例, 并使正例与负例的数量相等.首先, 利用距离计算公式‖α(h⊥+r-t⊥)+(1-α)(h+r-t)‖22, 计算头、尾实体间的距离, 得到嵌入向量; 然后, 根据‖eS-eI‖22<θ找到更多的对齐实体对; 最后, 更新损失函数, 将新找到的对齐实体对添加进对齐种子实体对集合L中, 并进行下一轮的迭代训练.算法描述如下:
step 1:训练集S = {(hS, r, tS), (hS, r, tI)}∪{(hI, r, tS), (hI, r, tI)}//文本实体集合EI, 图像实体集合ES, 关系集合R, 最小间隔γ, 嵌入维度k;
step 2:对齐种子集合L=(eS, eI) // eS∈ES, eI∈EI;
step 3: r←每种关系r∈R初始化嵌入;
step 4: e←每个实体e∈{EI, ES}初始化嵌入;
step 5: 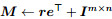
step 6: e⊥←Me+Im×n;
step 7: Sbatch← Sample(S, b)//小批量取样;
step 8: Tbatch ← ∅//初始化三元组集合;
step 9: for (h, r, t)∈Sbatch do
(h', r, t')← Sample(S'(h, r, t)) //打破正确三元组, 生成负例
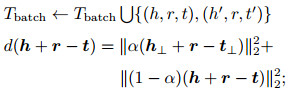
|
step 10: for eS∈ES do
for eI∈EI do //为每个图像实体遍历文本实体集合并计算距离
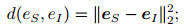
|
step 11: Align←(minnd(eS, eI))<θ //对计算结果进行排序;
step 12:嵌入向量
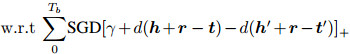
|
//使用SGD随机梯度下降方法优化参数;
step 13:实体对齐种子集合L←L∪ Align;
step 14: hS, hI, tS, tI, r //此时得到的图像实体表示向量和文本实体表示向量都带有相应的语义信息和对齐信息.
4 实验分析 4.1 数~据~集本文构建一个包含图像和文本的多模态数据集WN18-IMG. WN18-IMG中的文本数据来自于文本知识库WordNet, 图像数据来自于图像知识库ImageNet, 并将WN18-IMG随机分为训练集、测试集和验证集.为了保证能够实现多模态实体对齐, 应使WN18-IMG中所有的图像实体都有对应的文本实体.由于在构建WN18-IMG数据集时没有设置明显的负例, 本文将遵循以往知识表示学习模型[8, 16, 25, 37]的负例生成方法, 把三元组中的头实体和尾实体随机替换形成负例, 且使正例与负例数量相等.同时, 为了能够验证本文所提出的方法具有普遍适用性, 还使用WN9-IMG[37]进行了对比实验.数据集统计信息如表 1所示.
| 表 1 数据集统计信息 |
本文使用VGGNet实验中得到的图像识别最优参数, 这样可节省大量数据预处理时间.此外, 本文采用随机梯度下降法(SGD)对上述方法的值进行最优化处理.对于本文提出的JKRL模型中正例、负例之间最小间隔γ设置为{0.5, 1.0, 1.5, 2.0}, 经验学习率设置为0.001[8, 21], 迭代次数设定为{500, 1 500, 2 500, 3 500, 4 500}, θ设置为{ 0.5, 1.0, 2.0, 3.0, 4.0}, 对于网格搜索的步长k设置为{ 0.05, 0.10, 0.15, 0.20}.在实验中用于对比实验的TransE和TransD模型的参数依据原论文进行设置.在本文中, 图像特征向量di为4 096, 关系和实体嵌入维数n设置为100.通过实验得到本模型的最优参数为γ=1.0, k=0.5, θ=1.0.
本文的实验是在配置了Intel Xeon E5-1620 3.6 GHz的CPU, Nvidia GeForce GTX 1070 Ti的GPU和32 GB内存的个人工作站上进行的, 操作系统为Ubuntu.
4.3 多模态实体对齐 4.3.1 评价标准多模态实体对齐任务的目的是判断不同模态数据中相同或相似的实体能否建立一定的对齐关系.以往实体对齐任务使用正确实体得分函数的平均排名(mean rank of correct entity, MR)和预测结果前10项(Hit@10)、前1项(Hit@1)实体的准确率作为评价标准, 因此, 本文也使用Hit@10、Hit@1和MR作为多模态实体对齐的评价标准.为了进行对比实验, 本文使用MTransE效果较好的两个模型(基于翻译的模型和基于线性变化的模型).同时, 在传统表示学习模型TransE和TransD对多模态数据进行嵌入的基础上, 使用迭代对齐规则(IEA)实现多模态实体对齐的实验来进一步验证ITMEA方法的有效性.本文将MTransE的两个模型分别命名为MTransE(T)和MTransE (L), 将使用迭代对齐规则的TransE和TransD模型命名为TransE+IEA和TransD+IEA.
4.3.2 实验结果表 2中给出了在多模态数据集WN18-IMG和WN9-IMG上Hit@10、Hit@1和MR的结果.从表 2中可以看出:
| 表 2 多模态实体对齐结果 |
1) TransE+IEA、TransD+IEA和ITMEA的结果优于MTransE (T)和MTransE (L)方法.由此可以说明, 通过迭代学习少量已对齐的多模态之间的关系便能够对实体对齐的结果有所提升, 且能够大大减少标注数据的工作量.
2) 在使用迭代对齐规则的方法中, ITMEA的结果与TransE+IEA和TransD+IEA的结果相比, 在一定程度上有所提升.这也验证了本文之前介绍的传统表示学习模型在对多模态数据进行嵌入表示时, 在一定程度上会损失掉一些视觉信息从而影响对齐结果.同时, 结合多种表示学习模型的优点能够实现更加精准的实体对齐.
图 4展示了在WN9-IMG数据集上, 不同模型迭代相同次数的耗时情况.从图 4中可以看出MTransE(T)耗时最短, 而本文提出的ITMEA方法耗时最长. MTransE(T)模型直接进行不同模态实体间的相互计算, 且使用TransE进行训练, 其时间复杂度为O(Nt).同样, 进行不同模态实体间相互计算的MTransE(L)模型由于需要进行线性变换, 其时间消耗比MTransE(T)长.然而, 本文提出的ITMEA方法由于结合了TransE和TransD两种距离计算方法且迭代对齐不同模态实体, 其时间复杂度高于对比模型, 导致耗时较长.

|
图 4 不同算法时间消耗 |
三元组分类任务的目的是判断给定的三元组(h, r, t)是否正确, 其本质是一个二分类问题.本文为每种关系设置一个专用的阈值δr, 使用验证集对阈值δr进行优化.在测试阶段, 使用3.2节中提出的损失函数对测试集中每个三元组进行计算, 当得分小于阈值时判断为分类正确, 否则认为错误.同时, 为了验证添加图像信息是否有助于三元组分类的效果, 使用未添加图像信息的WordNet的子集WN11来进行对比.
4.4.2 实验结果表 3中给出了TransE、TransD和JKRL知识表示学习模型, 在WN11、WN18-IMG和WN9-IMG三个数据集上进行三元组分类的实验结果.纵向对比表 3中的结果可以看出:在WN18-IMG和WN9-IMG多模态数据集上, JKRL模型均优于TransE和TransD模型; 但在纯文本数据集上, JKRL模型优于TransE模型但低于TransD模型.这是由于JKRL模型为每种模态的数据分别学习了相应权重, 但对单模态数据进行嵌入时损失了部分信息, 从而造成三元组分类结果降低.横向对比三元组分类结果可以发现, 任意一种知识表示学习模型在多模态数据集WN18-IMG和WN9-IMG上得到的结果均优于单模态数据集WN11.由此表明, 向文本中添加图像信息能够提升三元组分类任务的准确率.
| 表 3 三元组分类结果 |
图 5展示了在WN18-IMG多模态数据集中, 三元组分类结果随迭代次数的变化情况.可以看出, 随着迭代次数的增加, 三元组分类的准确率不断提升, 但迭代3 500次之后, 增长的趋势有所减缓.

|
图 5 三元组分类准确率 |
链接预测的目的是当结构化三元组中缺失头实体、关系或尾实体中的任意一个时, 均能够成功预测缺失的实体或关系.链接预测主要关注的是实体预测, 这个任务被广泛应用于知识表示学习模型的评价中.本文使用两种评价标准作为评测指标: 1)正确实体得分函数的平均排名(mean rank of correct entity, MR); 2)前10个实体的正确率(Hit@10).此外, 本文还遵循TransE模型中使用的“raw”和“filter”两个评估指标.其中: “raw”表示原始未经处理的数据, 而“filter”表示删掉负例生成环节中产生的正确三元组数据(也称“污染”三元组).与其相比, 在本文实验中还使用了文献[38]提出的无类型约束(TransE(N)、TransD(N)、JKRL(N))和有类型约束(TransE、TransD、JKRL)两个指标作为评价标准.其中, 有类型约束指的是为每种关系固定好头实体和尾实体的类型.
4.5.2 实验结果图 6展示了在WN18-IMG多模态数据集中, 正确实体得分函数的平均排名(MR)随迭代次数的变化趋势.可以看出, 随着迭代次数的增加, 正确实体得分函数的平均排名(MR)逐渐降低并趋于稳定.且TransE、TransD和JKRL模型的值优于TransE(N)、TransD(N)、JKRL(N)的值.

|
图 6 MR随迭代次数的变化 |
在WN18-IMG多模态数据集中, Hit@10准确率随迭代次数的变化情况如图 7所示.从图 7中可以看出, 随着迭代次数的增加, Hit@10的准确率不断提升, 同时TransE、TransD和JKRL模型的准确率均优于TransE(N)、TransD(N)、JKRL(N)的准确率.

|
图 7 Hit@10随迭代次数的变化 |
从图 6和图 7可以得出: 1) JKRL模型在处理实体链接预测任务上优于TransE、TransD模型, 说明对于多模态数据的嵌入需要更加有效的知识表示学习模型; 2)对实体的类型进行约束能够提升实体链接预测的效果.
表 4中进一步展示了MR和Hit@10在多模态数据集WN18-IMG和WN9-IMG上取得的最优值.从表 4中可以发现: 1) JKRL模型在MR和Hit@10上取得的结果均优于TransE和TransD模型, 说明知识表示学习模型JKRL能够帮助多模态数据的嵌入; 2)在相同数据集中, 有类型约束的实验结果与无类型约束的实验结果相比有较为明显的提升, 说明对实体的类型进行约束有助于提高知识表示学习的效果; 3)使用任意一种知识表示学习模型对多模态数据进行嵌入, 删掉其他正确实体后的结果明显优于未经过处理的数据, 说明对数据进行预处理有助于实体链接预测结果的提升.
| 表 4 实体链接预测结果 |
现有基于知识表示学习的实体对齐方法处理数据模态较为单一, 为此, 本文提出了一种基于联合知识表示学习的多模态实体对齐方法ITMEA.在理论价值方面, ITMEA使用联合知识表示学习模型JKRL, 将图像知识和文本知识嵌入到统一低维语义空间, 通过IEA方法迭代学习对齐种子实体集合中已对齐多模态实体间的关系, 并将学习到的关系应用到全部实体中以实现多模态实体对齐.实验结果表明, 本文提出的多模态实体对齐方法与现有实体对齐方法相比, 对齐准确率在一定程度上有所提升.此外, 本文在多模态数据集上使用实体链接预测和三元组分类对所提出的JKRL模型进行评价.实验结果显示, JKRL模型优于基准线.在应用价值方面, 本文提出的多模态实体对齐方法有助于开放的多模态知识图谱构建, 同时为跨模态检索和视觉问答等领域提供了新的思路和方法.
本文对迭代过程中新找到的对齐实体未进行置信度评估, 这可能会将错误的多模态实体对添加到种子集合中, 从而影响之后的迭代效果.为了解决这一问题, 后续工作将从以下几点入手: 1)引入软规则方法对新对齐的实体对进行置信度评估; 2)探究更加有效的知识表示学习模型, 使多模态知识实现最优嵌入; 3)研究更高效的图像特征提取模型并引入注意力机制, 从而实现图像实体特征的精确提取.
| [1] |
Yang F, Yang Z L, CohenW W. Differentiable learning of logical rules for knowledge base reasoning[C]. Proceedings of the International Conference on Neural Information Processing Systems. Long Beach: Curran Associates Inc, 2017: 2319-2328.
|
| [2] |
Dubey M, Banerjee D, Chaudhuri D, et al. EARL: Joint entity and relation linking for question answering over knowledge graphs[C]. Proceedings of the 17th International Semantic Web Conference. Monterey: Springer Int Publishing, 2018: 108-126.
|
| [3] |
Wang H W, Zhang F Z, Xie X, et al. DKN: Deep knowledge-aware network for new recommendation[C]. Proceedings of the 2018 World Wide Web Conference. Lyon: Springer Int Publishing, 2018: 1835-1844.
|
| [4] |
Suchanek F M, Kasneci G, Weikum G. Yago: A core of semantic knowledge[C]. Proceedings of the 2007 International world Wide Web Conference. Banff: Springer Int Publishing, 2007: 697-706.
|
| [5] |
Lehmann J, Isele R, Jakob M, et al. DBpedia — A large-scale, multilingual knowledge base extracted from wikipedia[J]. Semantic Web, 2015, 6(2): 167-195. |
| [6] |
Bollacker K, Evans C, Paritosh P, et al. Freebase: A collaboratively created graph database for structuring human knowledge[C]. Proceedings of the 14th ACM SIGMOD International Conference on Management of data. Vancouver: ACM, 2008: 1247-1250.
|
| [7] |
刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 247-261. (Liu Z Y, Sun M S, Lin Y K, et al. Knowledge representation learning: A review[J]. Journal of Computer Research and Development, 2016, 53(2): 247-261.) |
| [8] |
Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]. Proceedings of the International Conference on Neural Information Processing Systems. Lake Tahoe: Curran Associates Inc, 2013: 2787-2795.
|
| [9] |
Antol S, Agrawal A, Lu J, et al. VQA: Visual question answering[C]. Proceedings of the IEEE International Conference on Computer Vision. Chile: IEEE, 2015: 2425-2433.
|
| [10] |
Huang F Q, Zhang X M, Xu J, et al. Network embedding by fusing multimodal contents and links[J]. Knowledge-Based Systems, 2019, 171: 44-55. DOI:10.1016/j.knosys.2019.02.003 |
| [11] |
Liu W, Liu J, Wu M, et al. Representation learning over multiple knowledge graphs for knowledge graphs alignment[J]. Neurocomputing, 2018, 320: 12-24. DOI:10.1016/j.neucom.2018.08.070 |
| [12] |
赵军, 刘康, 何世柱, 等. 知识图谱[M]. 北京: 高等教育出版社, 2019: 1-254. (Zhao J, Liu K, He S Z, et al. Knowledge graph[M]. Beijing: Higher Education Press, 2019: 1-254.) |
| [13] |
Chen M H, Tian Y, Chang K W, et al. Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment[C]. Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: Morgan Kaufmann Inc, 2018: 3998-4004.
|
| [14] |
Xu K, Wang L W, Yu M, et al. Cross-lingual knowledge graph alignment via graph matching neural network[C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019: 3156-3161.
|
| [15] |
Sun Z Q, Hu W, Zhang Q H, et al. Bootstrapping entity alignment with knowledge graph embedding[C]. Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: Morgan Kaufmann Inc, 2018: 4396-4402.
|
| [16] |
Ji G, He S, Xu L, et al. Knowledge graph embedding via dynamic mapping matrix[C]. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistic. Beijing: ACL, 2015: 687-696.
|
| [17] |
Mahdisoltani F, Biega J, Suchanek F M. Yago3: A knowledge base from multilingual wikipedias[C]. Proceedings of the 7th Biennial Conference on Innovative Data Systems Research. Asilomar: ACM, 2013.
|
| [18] |
王雪鹏, 刘康, 何世柱, 等. 基于网络语义标签的多源知识库实体对齐算法[J]. 计算机学报, 2017, 40(3): 701-711. (Wang X P, Liu K, Heng S Z, et al. Multi-source knowledge bases entity alignment by leveraging semantic tags[J]. Chinese Journal of Computers, 2017, 40(3): 701-711.) |
| [19] |
Wang Z, Li J. Boosting cross-lingual knowledge linking via concept annotation[C]. Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing: Morgan Kaufmann Inc, 2013: 2733-2739.
|
| [20] |
Chen M H, Tian Y T, Yang M H, et al. Multi-lingual knowledge graph embeddings for cross-lingual knowledge alignment[J]. Proceedings of the 26th International Joint Conference on Artificial InI-17telligence. Melbourne: Morgan Kaufmann Inc, 2017, 1511-1517. |
| [21] |
Zhu H, Xie R B, Liu Z Y, et al. Iterative entity alignment via joint knowledge embeddings[C]. Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: Morgan Kaufmann Inc, 2017: 4258-4264.
|
| [22] |
Pershina M, Yakout M, Chakrabarti K. Holistic entity matching across knowledge graphs[C]. Proceedings of the IEEE International Conference on Cloud and Big Data Computing. Beijing: IEEE, 2015: 1585-1590.
|
| [23] |
Sun Z Q, Hu W, Li C K. Cross-lingual entity alignment via joint attribute-preserving embedding[C]. Proceedings of the 16th International Semantic Web Conference. Vienna: Springer, 2017: 628-644.
|
| [24] |
Socher R, Chen D, Manning C D, et al. Reasoning with neural tensor networks for knowledge base completion[C]. Proceedings of the International Conference on Neural Information Processing Systems. Lake Tahoe: Curran Associates Inc, 2013: 926-934.
|
| [25] |
Xiao H, Huang M, Meng L, et al. SSP: Semantic space projection for knowledge graph embedding with text descriptions[C]. Proceedings of the 31st Association for the Advancement of Artificial Intelligence. San Francisco: AAAI, 2017: 3104-3110.
|
| [26] |
Wang Z, Zhang J, Feng J, et al. Knowledge graph embedding by translating on hyperplanes[C]. Proceedings of the 28th Association for the Advancement of Artificial Intelligence. Québec: AAAI, 2014: 1112-1119.
|
| [27] |
Lin Y, Liu Z, Zhu X, et al. Learning entity and relation embeddings for knowledge graph completion[C]. Proceedings of the 29th Association for the Advancement of Artificial Intelligence. Hyatt Regency: AAAI, 2015: 2181-2187.
|
| [28] |
Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2d knowledge graph embeddings[C]. Proceedings of the 32nd Association for the Advancement of Artificial Intelligence. New Orleans: AAAI, 2018: 1811-1818.
|
| [29] |
Nguyen D Q, Nguyen T D, Nguyen D Q, et al. A novel embedding model for knowledge base completion based on convolutional neural network[C]. Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans: ACL, 2018: 327-333.
|
| [30] |
Pezeshkpour P, Chen L Y, Singh S. Embedding multimodal relational data for knowledge base completion[C]. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: ACL, 2018: 3208-3218.
|
| [31] |
Cui P, Liu S W, Zhu W W. General knowledge embedded image representation learning[J]. IEEE Transactions on Multimedia, 2017, 20(1): 198-207. |
| [32] |
Collell G, Zhang T, Moens M F. Imagined visual representations as multimodal embeddings[C]. Proceedings of the 35th Association for the Advancement of Artificial Intelligence. San Francisco: AAAI, 2017: 4378-4384.
|
| [33] |
Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248-255.
|
| [34] |
Miller G A. WordNet: A lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41. DOI:10.1145/219717.219748 |
| [35] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]. Proceedings of the International Conference on Learning Representations. San Diego: Arxive-prints, 2015: 1-14.
|
| [36] |
Shutova E, Kiela D, Maillard J. Black holes and white rabbits: Metaphor identification with visual features[C]. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego: ACL, 2016: 160-170.
|
| [37] |
Xie R B, Liu Z Y, Luan H B, et al. Image-embodied knowledge representation learning[C]. Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne: Morgan Kaufmann Inc, 2017: 3140-3146.
|
| [38] |
Han X, Cao S, Lv X, et al. OpenKE: An open toolkit for knowledge embedding[C]. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels: ACL, 2018: 139-144.
|