 2021, Vol. 36
2021, Vol. 36

2. 上海机电工程研究所,上海 201108
2. Shanghai Institute of Mechanical and Electrical Engineering, Shanghai 201108, China
为了解某种事物的发展规律, 人们通常会以一定的采样频率对该事物的某项指标进行观测, 这种按照时间先后顺序所产生的观测值集合就是时间序列.对时间序列的历史观测值进行分析, 并推测出未来时间节点上值的过程称为时间序列预测.时间序列预测已经应用于众多领域之中, 具有重要的现实意义.例如, 在生态环境领域, 可通过对日降水量进行预测来指导农业生产[1]; 在医疗领域, 可通过对疾病发病率进行预测来预防疾病传播[2]; 在经济领域, 可通过对房价进行预测来稳定国民经济和维护社会稳定[3].
传统时间序列预测方法利用统计学知识对时间序列表现出的发展过程、方向和趋势进行建模, 并以此模型为研究对象进行延伸和外推, 最终达到预测的目的.常用的传统时间序列预测模型主要包括AR模型、MA模型、ARMA模型和ARIMA模型.然而, 传统时间序列预测方法没有考虑外界影响因素和被预测对象间的因果关系, 而是将所有影响因素综合作用的结果归结到时间上, 仅从时间的维度对被预测对象建模.因此, 当某些影响因素发生较大变化时, 传统时间序列预测方法的预测精度会大大降低.
现代时间序列预测方法主要利用机器学习和深度学习技术对时间序列建模, 并利用模型进行预测.通过将时间序列的影响因素特征化, 现代时间序列预测方法可以捕获影响因素和被预测对象间的因果关系, 克服了传统时间序列预测方法的弊端, 大大提高了预测精度.在时间序列预测问题中常用的机器学习方法有支持向量机[4-5]、贝叶斯网络[6-7]、随机森林等[8-9].
相比于传统的机器学习方法, 深度学习方法无需人工提取特征, 且在面对大量数据样本时, 往往表现出更好的性能.因此, 越来越多的研究者利用深度学习方法来解决时间序列预测问题, 如BP神经网络[10-11]、长段时记忆网络(LSTM)[12-13]、卷积神经网络(CNN)[14-15]等.同时, 研究者们通过将一些新的理论和方法与已有神经网络模型进行结合来实现更好的预测效果, 其中注意力机制使用最为广泛.例如, 文献[16]使用一种基于注意力机制的LSTM进行股价预测, 大大提高了模型的预测效果.文献[17]提出了一种基于双阶段注意力机制的循环神经网络模型DA-RNN, 该模型基于编码器-解码器结构, 在编码器中引入输入注意力(input attention)机制来自适应地选择关联度更高的特征, 在解码器中引入时间注意力(temporal attention)机制来捕获时间序列的长期时间依赖.实验结果表明了DA-RNN具有优秀的预测能力, 但DA-RNN模型仍存在3点不足: 1)输入注意力机制中未考虑输入特征与被预测特征之间的相关性; 2)未考虑输入特征之间的相关性; 3)问题定义不符合实际情况.具体而言, 假设时间步长为T, DA-RNN需要由1至T时刻的输入特征组成的时间序列以及1至T-1时刻被预测特征组成的时间序列来预测出T时刻被预测特征的值.DA-RNN的问题定义存在的缺陷是: 在实际时间序列预测应用场景下, T时刻的输入特征值往往是获取不到的, 而在DA-RNN中, 该值是模型输入的一部分.
针对DA-RNN中存在的3个问题, 本文提出一种基于DA-RNN的改进模型DAFDC-RNN (dual-stage attention and full dimension convolution based recurrent neural network).DAFDC-RNN综合考虑了输入特征与被预测特征之间的相关性、被预测特征之间的相关性以及时间序列的长期时间依赖性, 同时修正了DA-RNN的问题定义中与实际应用场景不符的部分.实验部分首先确定模型的最佳超参数组合, 接着对模型部件的有效性进行验证, 最后通过对比实验对模型的预测性能进行验证.
1 DAFDC-RNN模型的构建 1.1 问题定义及符号表示DAFDC-RNN模型的输入有1至T-1时刻输入特征组成的多变量时间序列X和1至T-1时刻被预测特征组成的单变量时间序列Y.X=(x1, x2, ..., xt, ..., xT-1)=(x1, x2, ..., xk, ..., xn)T∈Rn×(T-1), Y=(y1, y2, ..., yt, ..., yT-1)T∈R(T-1)×1, T表示时间序列的步长, n表示输入特征的特征数量; xt∈Rn×1, 表示n个特征在t时刻的特征值集合; xk∈R(T-1)×1, 表示1至T-1时刻, 由第k个特征组成的时间序列; yt∈R, 表示被预测特征在t时刻的特征值.
DAFDC-RNN模型的目标是预测出T时刻被预测特征的特征值yT, 即需要学习一个非线性关系F, 使得F满足如下公式:
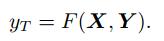
|
(1) |
DAFDC-RNN模型使用编码器-解码器结构, 在编码器中引入目标注意力(target attention)机制和全维度卷积(full dimension convolution, FDC)机制, 在模型解码器中引入时间注意力(temporal attention)机制.其中: target attention用于学习输入特征与被预测特征之间的相关性, FDC用于学习输入特征之间的相关性, temporal attention用于学习时间序列的长期时间依赖性.解码器的输出是模型的预测目标.DAFDC-RNN模型的结构如图 1所示.

|
图 1 DAFDC-RNN模型结构 |
某个特定时刻被预测特征的特征值是所有输入特征综合作用的结果, 即目标特征与输入特征之间具有一定的相关性, 并且通常情况下不同的输入特征与被预测特征之间的相关性大小也是不同的.例如, 假设一个多变量时间序列记录了某城市的空气质量情况, 输入特征包括空气中的含氧量、温度、气压、湿度、PM2.5浓度、SO2浓度等, 被预测特征是空气质量指数(AQI).通常情况下, 含氧量、温度、气压和湿度对空气质量指数的影响相对较小, 而PM2.5浓度、SO2浓度对空气质量指数的影响相对较大.DAFDC-RNN模型通过引入target attention机制来学习输入特征与被预测特征间的相关性.
为了量化t时刻模型输入中的第k个特征与被预测特征的相关性大小, 首先为第k个特征定义上下文向量contexttk, 有
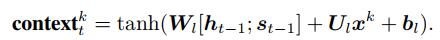
|
(2) |
其中: Wl、Ul和bl表示模型需要学习的参数, bl表示偏置项, Wl∈R(T-1)×2m, Ul∈R(T-1)×(T-1), bl∈R(T-1)×1, m表示编码器隐藏层的大小; [ht-1; st-1表示target attention处理xt时编码器的状态.由于[ht-1; st-1]与xk以线性相加的方式进行关联contexttk表示的是模型输入中第k个特征在编码器当前状态下的上下文表示.
为了将contexttk与被预测特征组成的时间序列Y之间建立关联, 引入注意力机制中的点积评分函数
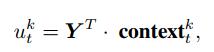
|
(3) |
其中utk表示在编码器当前状态下, 模型输入中第k个特征与被预测特征之间的相关性度量.最后引入Softmax函数将utk转化为权重atk, 有
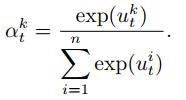
|
(4) |
根据模型为不同特征分配的权重, 可以得到t时刻target attention的输出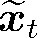
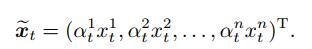
|
(5) |
为了描述方便, 记ctk=αtkxtk(k=1, 2, ..., n), 此时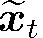
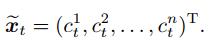
|
(6) |
对于一个多变量时间序列而言, 不同输入特征之间可能存在着相关性.以1.2.1节提到的记录某城市空气质量的时间序列为例, 温度、气压、湿度和PM2.5浓度都是输入特征, 且温度、气压和湿度都会对PM2.5浓度产生影响, 因此该时间序列的输入特征之间存在着相关性.时间序列数据可以看作是在固定时间间隔采样的一维网格数据, 可以利用卷积自主学习时间序列数据之间的相互关系.然而, 对于传统的带有卷积层、池化层和全连接层的CNN模型, 需要手动设置卷积核的大小和步长、池化窗口的大小和步长、全连接层的神经元数量等参数, 这些参数的设置大多依靠个人经验, 随机性比较强, 并且设置的参数是否可以充分学习特征之间的相关性, 往往无法得到很好的解释.本文针对多变量时间序列在特定时刻的特征值集合, 提出一种全维度卷积机制, 该机制不仅能够克服传统CNN模型需要手动设置大量参数的弊端, 同时可以充分学习输入特征之间的相关性.
全维度卷积(FDC)共分为3层, 分别是卷积层、池化层和Concat层.卷积层共包括n个卷积核, 维度分别为1, 2, ..., n-1, n, 对应的n个特征图维度分别为n, n-1, ..., 2, 1.使用大小不同的卷积核是为了充分提取特征之间的相关性.池化层分别对n个特征图进行平均池化(average pooling), 且池化窗口大小与特征图的维度一致, 即任意一个特征图经过池化层处理后的结果都是一个实数.Concat层将池化层产生的n个实数依次拼接, 拼接的结果就是FDC的最终输出.FDC中使用Concat层代替传统CNN模型中的全连接层, 不仅仅是为了避免手动设置神经元数量等参数, 更是为了防止全连接层破坏输入特征之间的相关性.下面对卷积层、池化层和Concat层中关键步骤的公式进行说明.
根据t时刻FDC的输入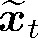
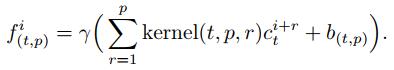
|
(7) |
其中: kernel(t, p, r)为t时刻卷积层第p个卷积核的第r个值; b(t, p)为偏置项; cti+r为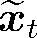
t时刻卷积层第k个特征图经池化层处理后的结果为
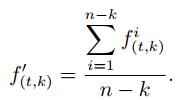
|
(8) |
t时刻池化层的输出分别为f(t, 1)′, f(t, 2)′, ..., f(t, n)′.Concat层将池化层的输出进行拼接后的结果为
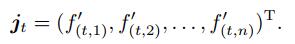
|
(9) |
随着输入序列长度的不断增加, 编码器-解码器结构的性能会迅速下降[18].为了解决这一问题, DAFDC-RNN模型在解码器中引入temporal attention机制, 自适应地选择相关的编码器隐藏层状态.
在任意时刻t, 解码器会利用temporal attention计算出一个上下文向量βt, 有
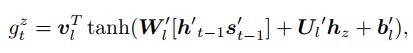
|
(10) |
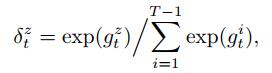
|
(11) |
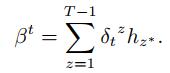
|
(12) |
其中: vl、Wl′、Ul′、bl′是模型需要学习的参数, bl′是偏置项, vl∈Rq×1, Wl′∈Rq×2n, Ul′∈Rq×m, bl′∈Rq×1, n表示解码器隐藏层大小; [ht-1′st-1′]表示解码器的当前状态, hz表示z时刻编码器隐藏单元状态.注意到[ht-1′st-1′]与hz以线性相加的方式关联, 因此gtz表示hz与当前时刻解码器状态的相关性度量.式(11)中, gtz通过Softmax函数转化为δtz, δtz是为hz分配的权重.如式(12)所示, 将1至T-1时刻编码器隐藏单元状态与隐藏单元对应的权重进行加权求和, 最终可以得到t时刻解码器的上下文向量βt.
1.2.4 模型输出通过感知器将解码器的上下文向量βt和被预测特征的特征值yt建立关联, 可以得到t时刻解码器隐藏层的输入为
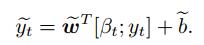
|
(13) |
其中:
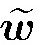
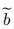
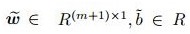
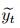
最后, 利用多层感知器将T-1时刻解码器的上下文向量βT-1和T-1时刻解码器隐藏单元状态hT-1′建立关联, 可以得到模型的最终输出为
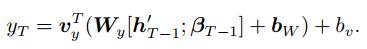
|
(14) |
其中: vy、Wy、bW、bv是模型需要学习的参数, bW和bv是偏置项, Wy∈Rq×(m+n), bW∈Rq×1, vy∈
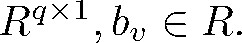
首先对输入的每个时间步xt引入目标注意力机制, 计算当前时间步的所有输入特征与被预测特征的相关性, 为不同的输入特征分配相应的权重atk, 从而得到t时间步目标注意力的输出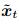
然后引入全维度卷积机制, 对t时间步学习输入特征
解码器的任意时刻通过引入时间注意力机制, 自适应地选择相关的编码器隐藏层状态h, 得到任意时刻的上下文向量β; 随后通过感知器将t时间步上下文向量βt和t时间步被预测特征的特征值yt建立关联, 可以得到t时刻解码器隐藏层的输入yt; 最后解码器依次通过t-1时间步的上下文向量βT-1和t-1时间步解码器隐藏单元状态hT-1′建立关联, 可以得到模型的最终输出yT.
1.4 算法效率分析DAFDC-RNN模型主要由目标注意力、全维度卷积和时间注意力3种机制来计算学习输入特征与被预测特征、输入特征之间和输入时间步之间的相关性.
在目标注意力机制每个时间步长, 计算每个特征上下文向量的浮点运算次数(FLOPs)为(T-1)(2m+1), 点积评分函数的FLOPs为(T-1).因此目标注意力机制的T(n)=(T-1)n((T-1)(2m+1)+(T-1)), 即T(n)=O((T-1)2).在全维度卷积机制每个时间步长, 卷积计算输出的FLOPs为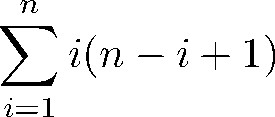
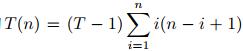
为了对DAFDC-RNN模型的预测性能进行验证, 本研究选取3个具有显著性差异特征的公开数据集: NASDAQ100(样本数为40 560, 特征数为81)、appliances energy prediction(简称AEP, 样本数为19 735, 特征数为27)、Beijing PM 2.5(样本数为43 824, 特征数为6)进行相关实验, 同时选取RMSE、MSE、MAPE作为模型的性能评价指标.此外, 本文采用箱线图分析检测异常值, 并用异常点前后的观测平均值进行代替, 采用0-1归一化法对时间序列进行归一化, 采用均值填充的方法对缺失值进行处理.
2.1 模型超参数DAFDC-RNN模型中共有3个超参数, 分别是时间步长T、编码器隐藏单元大小和解码器隐藏单元大小.为了实验方便, 本文假定编码器隐藏单元大小和解码器隐藏单元大小相等, 记为H.因此, 最终模型超参数实验需要确定T和H两个超参数.
给定T的取值集合为{4, 6, 8, 10, 12, 14}, H的取值集合为{16, 32, 64, 128, 256}, 理论上单个数据集需要进行30(6×5)次实验才可以确定T和H的最佳组合.本研究对超参数实验过程进行简化: 当对T的取值进行实验时, 固定H的值为64;当对H的取值进行实验时, 固定T的值为10.最终单个数据集需要进行11 (6+5)次实验就可以确定T和H的最佳组合.实验结果如图 2所示.

|
图 2 DAFDC-RNN模型超参数实验结果 |
由图 2(a)~图 2(c)可知, 对于时间步长T, 在一定范围内随着T的增加, 模型性能表现出逐渐上升的趋势, 当到达一定值之后, 随着T的增加, 模型性能逐渐下降.这是由于在一定范围内随着T的增加, 编码器可以对更多的输入数据进行编码, 解码器可利用的输入信息也越来越多, 模型的性能自然表现出上升的趋势.但是当T值超出一定范围之后, 解码器无法完全捕获时间序列的长期时间依赖, 导致模型性能逐渐下降.由图 2(d)~图 2(f)可知, 对于隐藏单元大小H, 随着H的增加, 模型性能表现出上升的总体趋势.同时注意到, 在AEP数据集和Beijing PM2.5数据集中, H为256时的模型性能比H为128时的模型性能要差.这是由于AEP数据集和Beijing PM2.5数据集特征数量相对较少, 而隐藏单元维度过大, 最终导致过拟合.
由图 2可知, 对于NASDAQ100数据集, 当T=12, H=256时模型性能最佳; 对于AEP数据集, 当T=12, H=128时模型性能最佳; 对于Beijing PM2.5数据集, 当T=8, H=128时模型性能最佳.
2.2 模型部件验证由上述可知, DAFDC-RNN模型有target attention、FDC和temporal attention三个核心部件.为了验证3个部件在模型中的有效性和作用, 本节设计了如下4种部件组合方式:
1)target attention+temporal attention;
2)target attention+FDC;
3)temporal attention+FDC;
4)target attention+FDC+temporal attention.
将以上4种部件组合方式分别记为model I、model II、model III和model IV, 分别在3个数据集上进行实验, 实验结果如表 1所示.
| 表 1 模型部件验证实验结果 |
由表 1可知, model IV在NASDAQ100和AEP数据集共6个评价指标上均取得了最佳效果.通过对比model I和model IV的部件组合方式, 可以看出FDC在NASDAQ100和AEP数据集上均能提升模型性能.同理, 通过对比model II和model IV以及model III和model IV的部件组合方式, 可以看出temporal attention和target attention在NASDAQ100和AEP数据集上能够提升模型性能.然而, 在Beijing PM2.5数据集中, model I的预测精度要高于model IV, 这是由于Beijing PM2.5数据集特征较少, 特征间相关性程度比较低, 而FDC充分学习了输入特征之间的相关性.也就是说, FDC适合处理特征间相关性程度比较高的时间序列, 在特征较少或特征间相关性程度比较低的时间序列中使用FDC反而会降低预测精度, 因此是一种类似于过拟合的现象.同时, 注意到在Beijing PM2.5数据集中, model IV的预测精度依旧高于model II和model III, 表明temporal attention和target attention在Beijing PM2.5数据集中依旧可以提高模型的性能.
2.3 对比实验为了进一步验证DAFDC-RNN模型的预测能力, 本节选用以下3种对比模型与DAFDC-RNN模型的预测效果进行对比: 1) ARIMA; 2) Encoder-Decoder(也称为Seq2seq); 3) DA-RNN.
需要注意的是, Encoder-Decoder和DA-RNN模型与DAFDC-RNN模型一样有时间步长T和隐藏单元大小H两个超参数.为了保证实验的公平性, 同样需要确定Encoder-Decoder和DA-RNN模型两个对比模型的最佳超参数组合, 实验结果如图 3所示.

|
图 3 Encoder-Decoder和DA-RNN模型的超参数实验结果 |
由图 3可知: 对于NASDAQ100数据集, 当T=10, H=128时, Encoder-Decoder和DA-RNN模型效果都是最佳.对于AEP数据集, 当T=10, H=64时, Encoder-Decoder模型效果最佳; 当T=10, H=128时, DA-RNN模型效果最佳.对于Beijing PM2.5数据集, 当T=10, H=64时, Encoder-Decoder模型效果最佳; 当T=8, H=128时, DA-RNN模型效果最佳.
最终, 所有模型在测试集上的实验结果如表 2所示.在该实验中, 将测试集和非测试集分别设为85%和15%.由表 2可知, DAFDC-RNN模型在NASDAQ100和AEP数据集共6个评价指标上取得了最佳效果; 在Beijing PM2.5数据集上只有MAPE指标取得最佳效果, 在RMSE和MSE上的效果略差于DA-RNN, 具体原因在2.2节已经提到, 即由于Beijing PM2.5数据集特征数量比较少, 而FDC充分学习了输入特征之间的相关性, 在特征较少或者特征间相关性程度比较低的时间序列中使用FDC反而会降低预测精度, 因此是一种类似于过拟合的现象.
| 表 2 对比实验结果 |
本文利用深度学习技术对时间序列的相关特性进行建模, 提出了一种称为DAFDC-RNN的时间序列预测模型, 并通过相关实验对DAFDC-RNN的预测能力进行了验证.实验结果表明, DAFDC-RNN在大特征量数据集下具有更加优秀的预测效果.该模型有望应用于现实各领域中的时序数据预测任务, 具有一定的应用前景和推广价值.
| [1] |
Das M, Ghosh S K. BESTED: An exponentially smoothed spatial bayesian analysis model for spatio-temporal prediction of daily precipitation[C]. International Conference on Advances in Geographic Information Systems. New York: ACM, 2017: 1-4.
|
| [2] |
El-Shafeiy E A, El-Desouky A I, El-ghamrawy S M. Prediction of liver diseases based on machine learning technique for big data[C]. International Conference on Advanced Machine Learning Technologies and Applications. Cairo: Springer, 2018: 362-374.
|
| [3] |
Wang J, Wun K Y, Kin L F. Gaussian process kernels for noisy time series: Application to housing price prediction[C]. International Conference on Neural Information Processing. Siem Reap: Springer, 2018: 78-89.
|
| [4] |
Chen T T, Lee S J. A weighted LS-SVM based learning system for time series forecasting[J]. Information Sciences, 2015, 299: 99-116. DOI:10.1016/j.ins.2014.12.031 |
| [5] |
Wang Y, Li L, Xu X. A piecewise hybrid of ARIMA and SVMs for short-term traffic flow prediction[C]. International Conference on Neural Information Processing. Guangzhou: Springer, 2017: 493-502.
|
| [6] |
Das M, Ghosh S K. sem Bnet: A semantic Bayesian network for multivariate prediction of meteorological time series data[J]. Pattern Recognition Letters, 2017, 93: 192-201. DOI:10.1016/j.patrec.2017.01.002 |
| [7] |
基于贝叶斯网络的混沌时间序列预测[J]. 计算机工程与应用, 2012, 48(13): 100-104. (Zhu Y Y, Yang Y L, Zhang H W. Prediction of chaotic time series based on Bayesian network[J]. Computer Engineering and Application, 2012, 48(13): 100-104.) |
| [8] |
Lin L, Wang F, Xie X, et al. Random forests-based extreme learning machine ensemble for multi-regime time series prediction[J]. Expert Systems with Applications, 2017, 83: 164-176. DOI:10.1016/j.eswa.2017.04.013 |
| [9] |
基于随机森林算法的用电负荷预测研究[J]. 计算机工程与应用, 2016, 52(23): 236-243. (Li W H, Chen H, Guo K. Research on electricity load forecasting based on stochastic forest algorithms[J]. Computer Engineering and Application, 2016, 52(23): 236-243. DOI:10.3778/j.issn.1002-8331.1606-0203) |
| [10] |
Ma L, Tian F. Pneumonia incidence rate predictive model of nonlinear time series based on dynamic learning rate BP neural network[C]. Fuzzy Information and Engineering. Huludao: Springer, 2010: 739-749.
|
| [11] |
基于粒子群优化BP网络的山区高速公路交通事故预测模型[J]. 电子科技, 2018, 31(10): 68-72. (Ji F, Xiong J, Yang W C. Traffic accident prediction model of mountain expressway based on particle swarm optimization BP network[J]. Electronic Technology, 2018, 31(10): 68-72.) |
| [12] |
Namini S S, Tavakoli N, Namin A S. A Comparison of ARIMA and LSTM in Forecasting Time Series[C]. International Conference on Machine Learning and Applications. Orlando: IEEE, 2018: 1394-1401.
|
| [13] |
Liu X, Liu Q, Zou Y, et al. A self-organizing LSTM-based approach to PM2.5 forecast[C]. International Conference on Cloud Computing and Security. Haikou: Springer, 2018: 683-693.
|
| [14] |
Koprinska I, Wu D, Wang Z. Convolutional neural networks for energy time series forecasting[C]. International Joint Conference on Neural Networks. Rio: IEEE, 2018: 1-8.
|
| [15] |
Binkowski M, Marti G, Donnat P. Autoregressive convolutional neural networks for asynchronous time series[C]. International Conference on Machine Learning. Stockholm: ACM, 2018: 579-588.
|
| [16] |
Cheng L C, Huang Y H, Wu M E. Applied attentionbased LSTM neural networks in stock prediction[C]. International Conference on Big Data. Seattle: IEEE, 2018: 4716-4718.
|
| [17] |
Qin Y, Song D, Chen H. A dual-stage attention-based recurrent neural network for time series prediction[C]. International Joint Conference on Artificial Intelligence. Mecbourne: AAAI Press, 2017: 2627-2633.
|
| [18] |
Cho K, Merrienboer B V, Bahdanau D, et al. On the properties of neural machine translation: Encoderdecoder approaches[C]. Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014: 103-111.
|